
[et_pb_section admin_label=”section”][et_pb_row admin_label=”row”][et_pb_column type=”4_4″][et_pb_text admin_label=”Text” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” text_font_size=”13″ text_line_height=”1.6em”]
 This is a guest post by Rachel Paul in celebration of National Library Week 2016 and National Library Workers Day. Paul is the Supervisor in the Performing Arts and Media department for the University of Arkansas Libraries. She catalogs and maintains the digital repository of institutional concert recordings for the University of Arkansas Department of Music. For questions about this blog post or the Performing Arts and Media department, contact her at rlp001@uark.edu, or 479-575-5518. **UPDATE: Paul just won the 2016 Rookie of the Year Award during the University of Arkansas Libraries National Library Workers Day Award Ceremony! Congratulations!
This is a guest post by Rachel Paul in celebration of National Library Week 2016 and National Library Workers Day. Paul is the Supervisor in the Performing Arts and Media department for the University of Arkansas Libraries. She catalogs and maintains the digital repository of institutional concert recordings for the University of Arkansas Department of Music. For questions about this blog post or the Performing Arts and Media department, contact her at rlp001@uark.edu, or 479-575-5518. **UPDATE: Paul just won the 2016 Rookie of the Year Award during the University of Arkansas Libraries National Library Workers Day Award Ceremony! Congratulations!
[/et_pb_text][et_pb_text admin_label=”Text” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
So, what is linked data? Tim Berners-Lee (July 2006), wrote an article for W3C (World Wide Web Consortium) where he outlined the concept of Linked Data. He listed four principles. 1. Use URIs as names for things. 2. Use HTTP URIs so people can look up those names for things. 3. When someone looks up a URI provide useful information using the standards RDF and SPARQL. 4. Include links to other URIs so people can discover more things (probably the most important principle for library data).
Okay, okay, so what does that mean? Well, currently most of the internet is made up of hypertext links that allow people to move from one document to another document, but with Linked Data, there are hyperdata links that allow people and machines to find data that is related to other data that was not previously linked. Basically, rather than people creating these little desert-island documents on the web, everything can become interconnected. Who knows how data can be used after it is all interconnected in this way, but as Berners-Lee says, “It is the unexpected re-use of information which is the value added by the web.”
What does that mean for libraries?
Enter BIBFRAME.
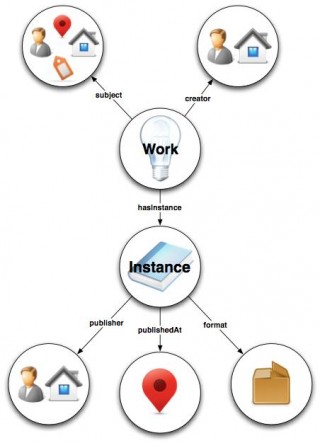 What exactly is BIBFRAME? It stands for the Bibliographic Framework Initiative. Let’s simplify. BIBFRAME is a model for bibliographic information that allows libraries to become part of the World Wide Web.
What exactly is BIBFRAME? It stands for the Bibliographic Framework Initiative. Let’s simplify. BIBFRAME is a model for bibliographic information that allows libraries to become part of the World Wide Web.
In BIBFRAME, words (search terms) are tied together by relationships. Humans often search out information organically, tangentially, and occasionally, sporadically. BIBFRAME allows for modeling information in a way that compliments this type of organic thought. For example, I want to find items about the Civil War. Searching for “Civil War” in the library catalog will lead me to a plethora of items like books, journal articles, or films, and in times past, that would have been the end of my search.
Now, with BIBFRAME, the records for books, journal articles, films, etc. that pop up when I search for “Civil War”, will contain links to other terms (and therefore items) that are related to the Civil War – dates, people, places, etc., but also information on the publishers, where the items were published, and other items available in that same format.
Perhaps you are thinking that this is already available in a catalog record, through Subject Headings. You would be mostly correct, except BIBFRAME facilitates searching that is more akin to the internet site hopping we end up doing when we start with a simple Google search. Perhaps I start with a “Civil War” query, but end up looking at cartoons from the 1950s that feature characters based off of Civil War generals. Or, I may end up looking at cat videos (Let’s be honest, that happens.). The possibilities are endless. Also, it links library holdings up with the rest of the internet. That’s really the kicker.
With BIBFRAME incorporated into library data, when people query search engines, those search engines can pick up on the available library data. Meaning, if you searched Google for “Civil War heroes”, it would not only pull up all of the images, videos, websites, and blog posts associated with those keywords (on the internet), it would also pull up links to holdings in libraries. So, if you really wanted a book about Civil War heroes, but you didn’t want to buy it from Amazon, Barnes & Noble, Google Play or another seller, you wouldn’t have to do an additional search for that item in a library catalog. Google (or any search engine) would automatically pull up library catalog results for you.
The Library of Congress determines that BIBFRAME will allow libraries to become part of the web of data (p.4):
When users begin their information hunt with a search engine or social network, whose objective is to help users locate information, then cultural heritage organizations need to help those engines and networks direct users to answers, especially those held by libraries. The BIBFRAME model is intentionally designed to coordinate the cataloging and metadata that libraries create with these efforts, and connect with them. In short, the BIBFRAME model is the library community’s formal entry point for becoming part of a much larger web of data.
Transforming Library Searching
I can only speculate at this point, but I believe by incorporating library data into the larger web of data, libraries will finally accomplish what we’ve been striving for since the advent of search engines. Namely, we will remain relevant and at the forefront of information querying. Most people do not begin information searches at the library. Not anymore, and especially not younger people. A high school or college student’s first inclination is to Google.
Google is a noun, a verb, and a way of life for many of us. So by allowing search engines, like Google, to have access to library data, we bring that data directly to the people we want to patronize our facilities. Finally, modern day information seekers will be able to Google their way to library holdings. Not only that, but the catalog records we house will themselves be little universes of information, with links to objects related to the original query terms. As I said before, the possibilities here, are endless.
The Road Ahead
BIBFRAME, as I mentioned, is an initiative. It has not yet been implemented in the library-verse at large. BIBFRAME will serve as a replacement for MARC, the standards for bibliographic description that has been around since the 1960s. Naturally, this has caused some dissension in the ranks of catalogers. The biggest question seems to be, if this is a new format, why is BIBFRAME concentrating so much on mapping MARC fields? And, if we concede that we need to implement BIBFRAME, when should we move to BIBFRAME?
The Library of Congress provides answers to these and other frequently asked questions at their FAQ page. The answers to the above questions are: “The mapping activity is grounded on the premise that the millions of existing MARC records need to be able to be transformed into BIBFRAME resources, but BIBFRAME as a “format” is very different from MARC. MARC has been adapted to carry RDA data, and BIBFRAME is being developed with RDA data as a prominent content type. Both MARC and BIBFRAME also accommodate data recorded by other rules but the cataloging rules give them similarity. The repackaging is not of MARC data but of cataloging content data…BIBFRAME is far from an environment that we could move to yet. The model and its components are still in discussion and development – a work in progress. When it is more mature, vendors and suppliers will need time to adjust services to accommodate it. And then we can expect a mixed environment for some time.”
So, as in all things technical, we still have a ways to go, but BIBFRAME will be a very big next step in library metadata, and it will certainly transform the way people use library catalogs.
Further Reading and Additional Information:
- For Webcasts & Presentations
- For Information on the Implementation Testbed
- For Tools & Downloads
- To join the discussion/keep up to date, subscribe to the BIBFRAME Listserv
- For the most current developments
Resources Used for this Post:
- https://www.w3.org/standards/semanticweb/data
- https://www.w3.org/DesignIssues/LinkedData.html
- https://www.loc.gov/bibframe/
- https://www.loc.gov/bibframe/pdf/marcld-report-11-21-2012.pdf
- https://www.loc.gov/bibframe/faqs/#q08
- http://www.rdatoolkit.org/
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]